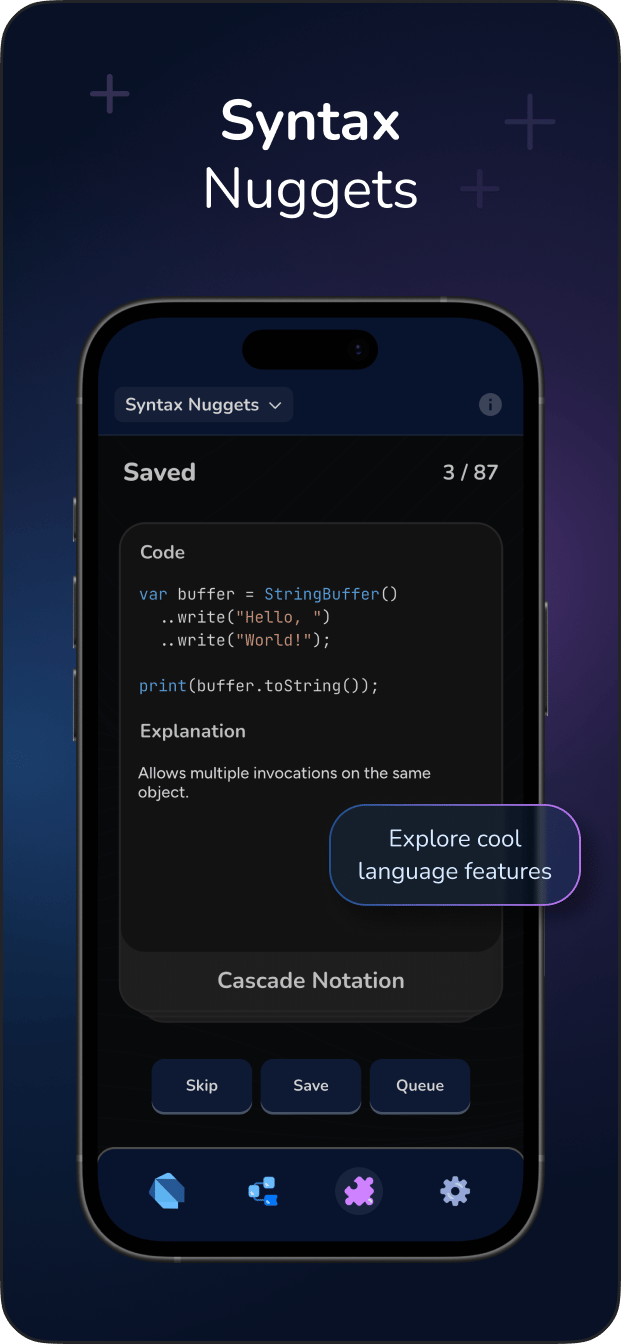
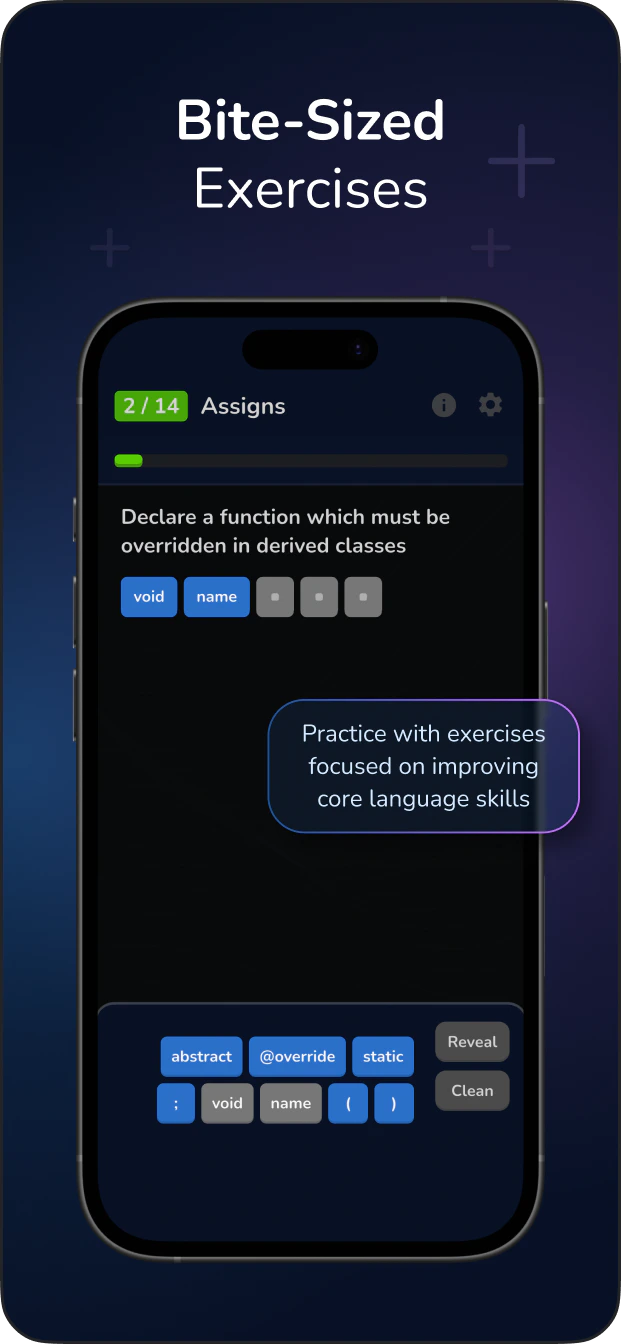
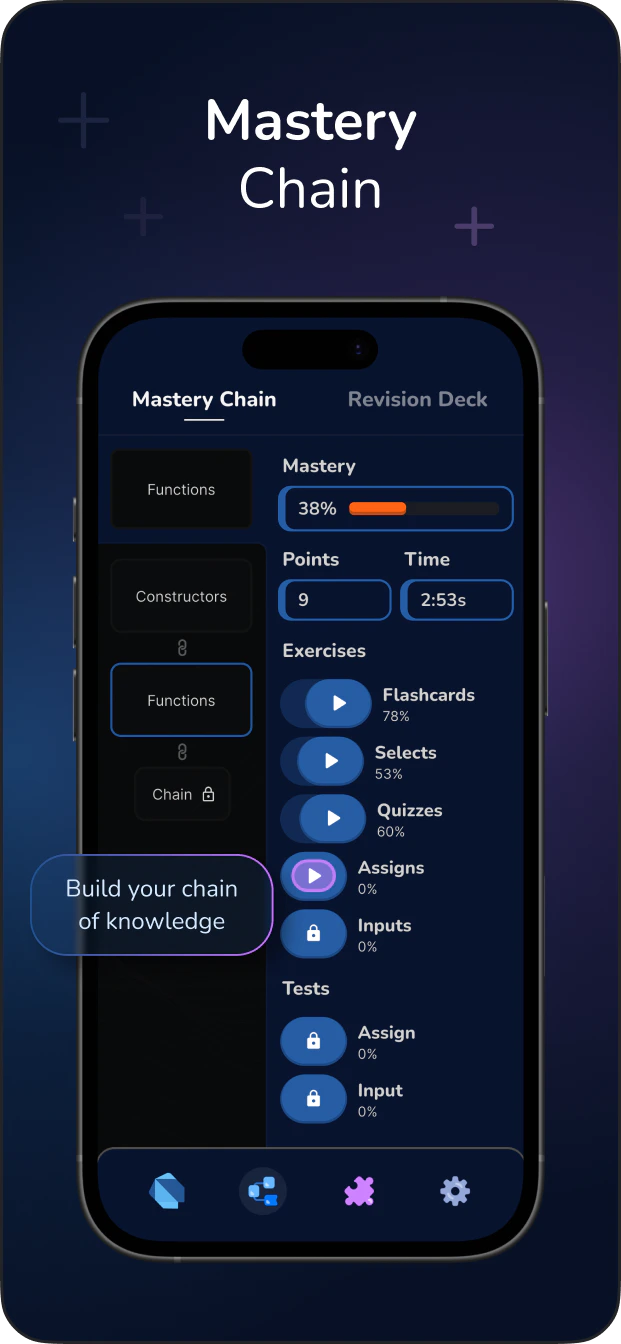
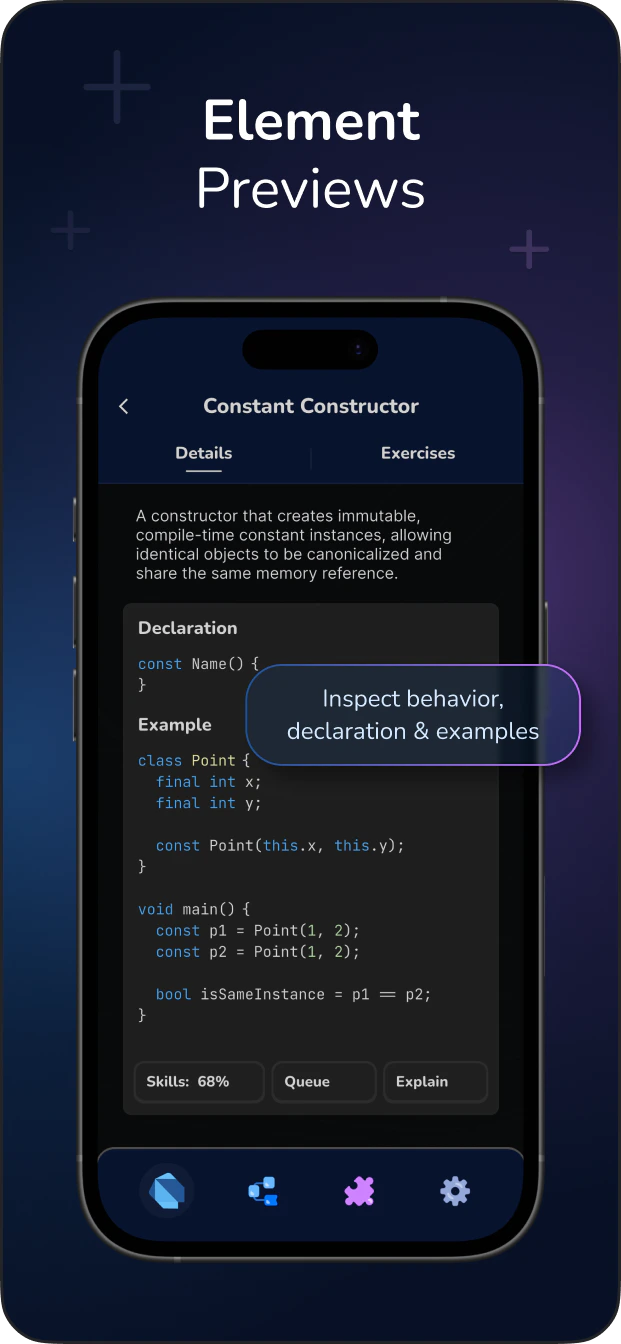
float type in Python is a built-in numeric data type used to represent real numbers with a fractional component. In CPython, a float is implemented as a C double, meaning it strictly adheres to the IEEE 754 double-precision binary floating-point standard. It occupies 64 bits of memory: 1 bit for the sign, 11 bits for the exponent, and 52 bits for the significand (mantissa).
Instantiation and Syntax
Floats can be instantiated using numeric literals containing a decimal point, scientific notation (E-notation), or the built-infloat() constructor.
Special Values
Thefloat type supports special IEEE 754 values representing infinity and undefined mathematical operations (Not a Number). These are typically instantiated via string casting.
Precision and Limits
Because Python floats are 64-bit double-precision values, they are subject to strict hardware limitations regarding maximum value and precision. These system-level constraints can be inspected using thesys module.
Representation Error
Because floats are stored as base-2 (binary) fractions, most base-10 (decimal) fractions cannot be represented exactly. This results in representation error, where the stored value is a highly precise approximation.Type Methods
Thefloat object includes several built-in methods for mathematical introspection and conversion.
Tired of Poor Python Skills? Fix That With Deep Grasping!Learn More